


The International Conference on Field-Programmable Logic and Applications (FPL) was the first and remains the largest conference covering the rapidly growing area of field-programmable logic and reconfigurable computing. During the past 25 years, many of the advances in reconfigurable system architectures, applications, embedded processors, design automation methods and tools were first published in the proceedings of the FPL conference series. The conference objective is to bring together researchers and practitioners from both academia and industry and from around the world.
The 26th edition took place in Lausanne, Switzerland, from 29th August 2016 until 2nd September 2016. Tutorials and Workshops ran Monday and Friday while Tuesday through Thursday took place the main conference.
.jpg "(C) Alain Herzog")
Venue
The conference was held on the EPFL campus in the brand-new Swiss Tech Convention Centre, a unique structure with a futuristic design. EPFL is one of the two Swiss Federal Institutes of Technology. With the status of a federal polytechnic university since 1969, the young engineering school has grown in many dimensions, to the extent of becoming a world renown institution of science and technology. EPFL is located in Lausanne in Switzerland, on the shores of the largest Alpine lake, Lake Geneva, and at the foot of the Alps, close to Mont Blanc. It is easy to reach by air through Geneva airport (more than 100 cities with non-stop flights, frequent comfortable direct trains from inside the airport to Lausanne in about 50 minutes) and through Zurich airport (connected non-stop to around 200 cities, frequent comfortable direct trains from inside the airport to Lausanne in about two hours and a half).
 Christophe Leyvraz")
Programme
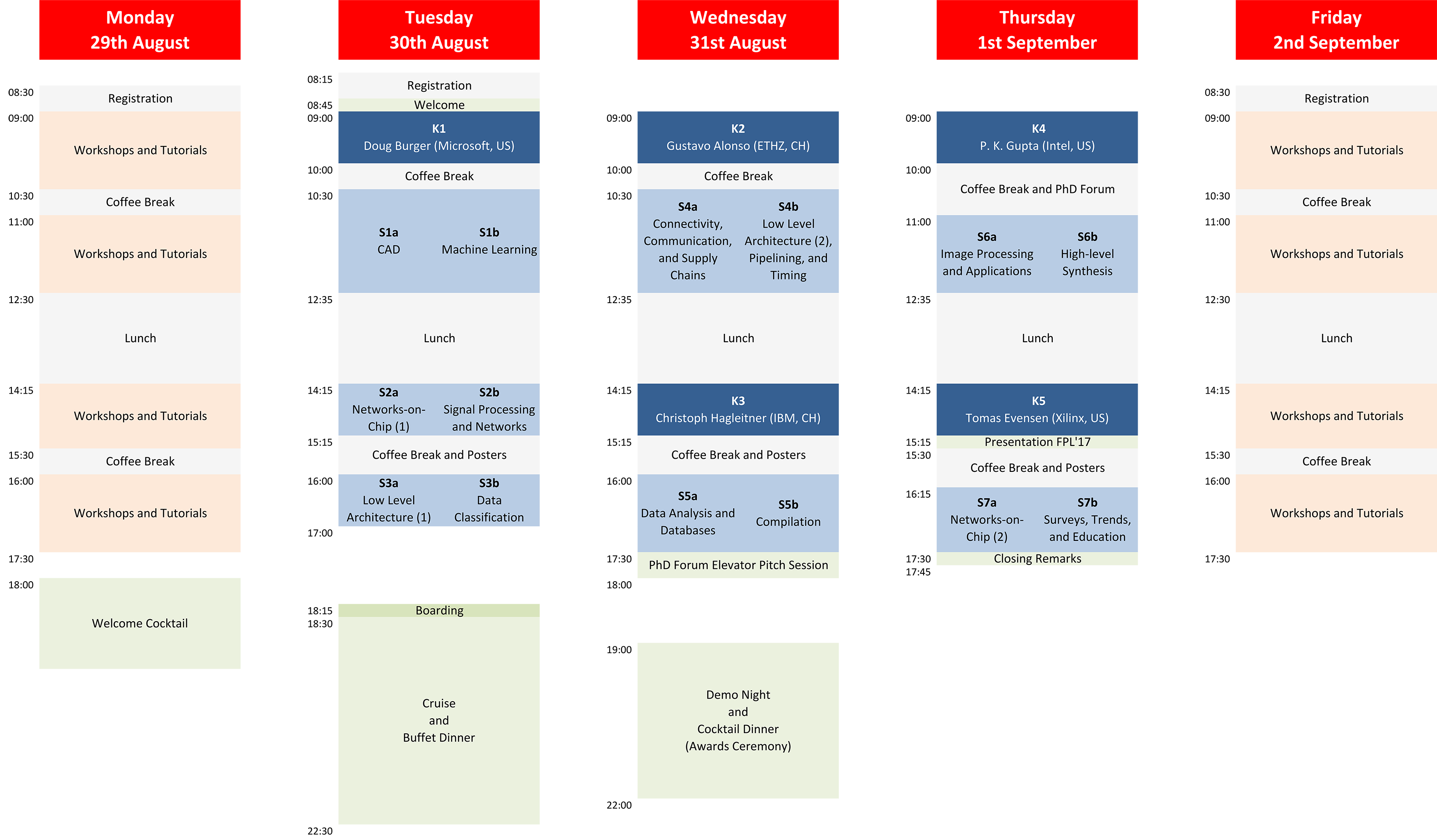
Click on the above overview for a PDF version. Below is the detailed programme of the main conference. Click paper titles in the detailed programme to access, when available, the presentation slides in PDF or PowerPoint format. Full papers are available through IEEE Xplore.
| Monday 29th August | |
|
Welcome Cocktail
6:00pm–7:30pm
BC Cafeteria |
|
| Tuesday 30th August | |
|
Registration
8:15am–8:45am
Foyer Grätzel |
|
|
Welcome
8:45am–9:00am
Auditorium B |
|
|
Keynote K1: Configurable Clouds
Doug Burger (Microsoft, US)
Chair: Paolo Ienne
9:00am–10:00am
Auditorium B |
|
|
Coffee Break
10:00am–10:30am
Foyer Grätzel |
|
|
Session S1a: CAD
Chair: Sinan Kaptanoglu
10:30am–12:35pm
Auditorium B |
|
| 10:30am |
1National University of Singapore, SG
2Technische Universitaet Dresden, DE |
| 10:55am |
Ghent University, BE
|
| 11:20am |
High-Speed PCAP Configuration Scrubbing on Zynq-7000
All Programmable SOCs
Brigham Young University, US
|
| 11:45am |
1 Nanyang Technological University, SG
2 Plunify, Inc., SG |
| 12:10pm |
Ghent University, BE
|
| 12:15pm |
Institute of Computing Technology, Chinese Academy of Sciences, CN
|
| 12:20pm |
Brno University of Technology, CZ
|
| 12:25pm |
1EPFL, CH
2University of California, Berkeley, US |
| 12:30pm |
Improving the Efficiency
of PUF-Based Key Generation in FPGAs Using
Variation-Aware Placement
University of Massachusetts, Amherst, US
|
|
Session S1b: Machine Learning
Chair: Alireza Kaviani
10:30am–12:35pm
Room 1ABC |
|
| 10:30am |
Fudan University, CN
|
| 10:55am |
Fudan University, CN
|
| 11:20am |
Hardware Acceleration of
Feature Detection and Description Algorithms on
Low-Power Embedded Platforms
Brown University, US
|
| 11:45am |
University of California, Riverside, US
|
| 12:10pm |
University of Coimbra, PT
|
| 12:20pm |
Intel, US
|
| 12:25pm |
Stony Brook University, US
|
| 12:30pm |
1IBM T. J. Watson Research Center, US
2University of Illinois at Urbana-Champaign, US |
|
Lunch
12:35pm–2:15pm
Le Parmentier |
|
|
Session S2a: Networks-on-Chip (1)
Chair: Dirk Stroobandt
2:15pm–3:15pm
Auditorium B |
|
| 2:15pm |
Nanyang Technological University, SG
|
| 2:40pm |
University of Toronto, CA
|
| 3:05pm |
ETHZ, CH
|
| 3:10pm |
1Universidad Autónoma de Madrid, ES
2Universidad Nacional de San Juan, AR |
|
Session S2b: Signal Processing and Networks
Chair: Francesco Regazzoni
2:15pm–3:15pm
Room 1ABC |
|
| 2:15pm |
Katholieke Universiteit Leuven, BE
|
| 2:40pm |
Efficient Processing of Phased Array Radar in Sense
and Avoid Application Using Heterogeneous Computing
Brigham Young University, US
|
| 3:05pm |
Modeling Considerations
for the Hardware-Software Co-design of Flexible
Modern Wireless Transceivers
Northeastern University, US
|
| 3:10pm |
1University of Kansas, US
2Catholic University of America, US |
|
Coffee Break and
Poster Session (from Sessions S1a, S1b, S2a, and S2b)
3:15pm–4:00pm
Foyer Grätzel |
|
|
Session S3a: Low Level Architecture (1)
Chair: Qiang Wang
4:00pm–5:00pm
Auditorium B |
|
| 4:00pm |
Ryerson University, CA
|
| 4:25pm |
University of Toronto, US
|
| 4:50pm |
University of Utah, US
|
| 4:55pm |
Université de Bordeaux, FR
|
|
Session S3b: Data Classification
Chair: Peter Cheung
4:00pm–4:55pm
Room 1ABC |
|
| 4:00pm |
1Nanyang Technological University, SG
2Hong Kong University of Science and Technology, HK |
| 4:25pm |
1IBM Research, Zurich, CH
2IBM Power Systems Performance Group, CA 3IBM T. J. Watson Research Center, US |
| 4:50pm |
1Tsinghua University, CN
2City University of Hong Kong, HK |
|
Cruise and Buffet Dinner
6:15pm–10:30pm
Ouchy |
|
| Wednesday 31st August | |
|
Keynote K2: Data Processing on the Fast Lane
Gustavo Alonso (ETHZ, CH)
Chair: Walid Najjar
9:00am–10:00am
Auditorium B |
|
|
Coffee Break
10:00am–10:30am
Foyer Grätzel |
|
|
Session S4a: Connectivity, Communication, and Supply Chains
Chair: Miriam Leeser
10:30am–12:35pm
Auditorium B |
|
| 10:30am |
1Fudan University, CN
2Imperial College London, UK |
| 10:55am |
Optimizing
Interconnection Complexity for Realizing Fixed
Permutation in Data and Signal Processing
Algorithms
University of Southern California, US
|
| 11:20am |
1University of Manchester, UK
2Mahindra École Centrale, IN 3University of Warwick, UK |
| 11:45am |
Johns Hopkins University, US
|
| 12:10pm |
High-Speed Programmable FPGA Configuration through
JTAG
Brigham Young University, US
|
| 12:15pm |
1Ritsumeikan University, JP
2Osaka University, JP 3NEC Corporation, JP 4Kyoto University, JP 5Kochi University, JP |
| 12:20pm |
1University of Patras, GR
2IBM Research, Zurich, CH |
| 12:25pm |
University of New South Wales, AU
|
| 12:30pm |
Télécom Bretagne, FR
|
|
Session S4b: Low Level Architecture (2), Pipelining, and Timing
Chair: Akash Kumar
10:30am–12:35pm
Room 1ABC |
|
| 10:30am |
1Sharif University of Technology, IR
2Karsruhe Institute of Technology, DE |
| 10:55am |
University of Toronto, CA
|
| 11:20am |
Xilinx Corporation, US
|
| 11:45am |
1Xilinx Corporation, US
2University of California, Santa Cruz, US |
| 12:10pm |
Tohoku University, JP
|
| 12:15pm |
Keio University, JP
|
| 12:20pm |
1Anadolu University, TR
2University of California, Santa Barbara, US |
| 12:25pm |
Linköping University, SE
|
| 12:30pm |
University of Manchester, UK
|
|
Lunch
12:35pm–2:15pm
Le Parmentier |
|
|
Christoph Hagleitner (IBM, CH)
Chair: Philip Brisk
2:15pm–3:15pm
Auditorium B |
|
|
Coffee Break and
Poster Session (from Sessions S3a, S3b, S4a, and S4b)
3:15pm–4:00pm
Foyer Grätzel |
|
|
Session S5a: Data Analysis and Databases
Chair: Sameh Assad
4:00pm–5:30pm
Auditorium B |
|
| 4:00pm |
IBM Research, Zurich, CH
|
| 4:25pm |
CERN, CH
|
| 4:50pm |
Imperial College London, UK
|
| 5:15pm |
ETHZ, CH
|
| 5:20pm |
Technical University of Crete, GR
|
| 5:25pm |
Fudan University, CN
|
|
Session S5b: Compilation
Chair: Andreas Koch
4:00pm–5:30pm
Room 1ABC |
|
| 4:00pm |
Arizona State University, US
|
| 4:25pm |
Friedrich-Alexander University Erlangen-Nürnberg, DE
|
| 4:50pm |
University of Toronto, CA
|
| 5:15pm |
1Imperial College London, UK
2INRIA, FR 3Harbin Institute of Technology, CN |
| 5:20pm |
University of Hong Kong, HK
|
| 5:25pm |
Nanyang Technological University, SG
|
|
PhD Forum Elevator Pitch Session
Chairs: Mirjana Stojilović and Yann Thoma
5:30pm–6:00pm
Auditorium B |
|
| 5:30pm |
1EPFL, CH
2Mahindra École Centrale, IN 3University of Warwick, UK |
| 5:33pm |
1University of Strathclyde, UK
2Edinburgh Cancer Research Centre, UK |
| 5:36pm |
EPFL, CH
|
| 5:39pm |
University of Queensland, AU
|
| 5:42pm |
University of Sao Paulo, BR
|
| 5:45pm |
Dimensionality Reduction of Hyperspectral Images
Using Reconfigurable Hardware
Complutense University of Madrid, ES
|
| 5:48pm |
Brno University of Technology, CZ
|
| 5:51pm |
1Supélec, FR
2IETR, FR 3Université Bretagne Sud, FR |
| 5:54pm |
Universidade de Aveiro, PT
|
|
Demo Night and Cocktail Dinner
(Awards Ceremony)
7:00pm–10:00pm
SV Hall |
|
|
Transparent FPGA Flow
HEIG‐VD, CH
|
|
|
A Runtime Reconfigurable FPGA-Based Microphone Array
for Sound Source Localization
Vrije Universiteit Brussel, BE
|
|
|
Demonstration of a Context-Switch Method for
Heterogeneous Reconfigurable Systems
Laboratoire TIMA, FR
|
|
|
XDL Alternative for Interfacing RapidSmith and
Vivado
Brigham Young University, US
|
|
|
HeteroSim: A Heterogeneous CPU-FPGA Simulator
Hong Kong University of Science and Technology, HK
|
|
|
Single-FPGA 3D Ultrasound Beamformer
EPFL, CH
|
|
|
Architectural Exploration and Implementation of an
Image Processing Chain with SpaceStudio
1Space Codesign Systems Inc., CA
2IRT Saint-Exupéry, FR |
|
|
Designing a Virtual Runtime for FPGA Accelerators in
the Cloud
1EPFL, CH
2Mahindra École Centrale, IN 3University of Warwick, UK |
|
| Thursday 1st September | |
|
Keynote K4: Accelerating Datacenter Workloads
P. K. Gupta (Intel, US)
Chair: Patrick Lysaght
9:00am–10:00am
Auditorium B |
|
|
Coffee Break and PhD Forum
10:00am–11:00am
Foyer Grätzel |
|
|
Session S6a: Image Processing and Applications
Chair: Nachiket Kapre
11:00am–12:35pm
Auditorium B |
|
| 11:00am |
University of Arizona, US
|
| 11:25am |
1Tsinghua University, CN
2Microsoft Research, Asia, CN |
| 11:50am |
University of Tsukuba, JP
|
| 12:15pm |
Imperial College London, UK
|
| 12:20pm |
1Zhejiang University, CN
2Hasselt University, BE |
| 12:25pm |
1Katholieke Universiteit Leuven, BE
2STMicroelectronics, BE |
| 12:30pm |
1George Mason University, US
2Cadence Design Systems, US |
|
Session S6b: High-level Synthesis
Chair: Mike Wirthlin
11:00am–12:35pm
Room 1ABC |
|
| 11:00am |
Politecnico di Milano, IT
|
| 11:25am |
Hong Kong Polytechnic University, HK
|
| 11:50am |
University of British Columbia, CA
|
| 12:15pm |
Center for Research and Development, Hellas (CERTH),
GR
|
| 12:20pm |
1Nanyang Technological University, SG
2University of Warwick, UK |
| 12:25pm |
University of Kassel, DE
|
| 12:30pm |
Vrije Universiteit Brussels, BE
|
|
Lunch
12:35pm–2:15pm
Le Parmentier |
|
|
Tomas Evensen (Xilinx, US)
Chair: Jason Anderson
2:15pm–3:15pm
Auditorium B |
|
|
Presentation FPL'17
3:15pm–3:30pm
Auditorium B |
|
|
Coffee Break and
Poster Session (from Sessions S5a, S5b, S6a, and S6b)
3:30pm–4:15pm
Foyer Grätzel |
|
|
Session S7a: Networks-on-Chip (2)
Chair: Dionisis Pnevmatikatos
4:15pm–5:30pm
Auditorium B |
|
| 4:15pm |
1INRIA, FR
2University of Massachusetts, Amherst, US |
| 4:40pm |
Sharif University of Technology, Iran
|
| 5:05pm |
1National University of Singapore, SG
2Technische Universität Dresden, DE |
|
Session S7b: Surveys, Trends, and Education
Chair: Kubilay Atasu
4:15pm–5:30pm
Room 1ABC |
|
| 4:15pm |
Hubert Curien Laboratory, Jean Monnet University, FR
|
| 4:40pm |
1Nanyang Technological University, SG
2Imperial College London, UK |
| 5:05pm |
National Technical University of Athens, GR
|
|
Closing Remarks
5:30pm–5:45pm
Auditorium B |
|
 LT / Régis Colombo")
Keynote Talks

Doug Burger
Microsoft, US
Configurable Clouds
(slides)
Hyperscale clouds are already disrupting the industry
in significant ways and are on their way to being a
trillion-dollar market. Reconfigurable computing
holds the promise of a transformation—not an
augmentation—of cloud architecture. In this
talk, I will describe the evolution of the Catapult
cloud FPGA architecture developed at Microsoft,
through its early prototypes, through previously
published designs, to the current v2
architecture that is successfully transforming our
cloud architecture at large scale. I will show why we
believe this particular design is disruptive, and will
describe a few case studies about how Microsoft is
using it to accelerate our both our services and our
Azure cloud platform. I will conclude with some
thoughts about how these
Configurable Clouds may evolve and some of the
future opportunities for large-scale reconfigurable
computing in general.
Doug Burger is a Distinguished
Engineer at Microsoft, where he leads several research
projects aimed at transforming the computing
architecture of Microsoft's systems and devices. With
Derek Chiou, he co-leads the Catapult project, which
is incorporating FPGA technology at large scale into
Microsoft's cloud architecture. Before joining
Microsoft in 2008, he served on the Computer Science
faculty at the University of Texas at Austin for ten
years, where he co-led the TRIPS project. He is the
recipient of the 2006 Maurice Wilkes Award, an IEEE
Fellow, an ACM Fellow, an ex-athlete, and an avid
father.

Gustavo Alonso
ETHZ, CH
Data Processing on the
Fast Lane
(slides)
Data processing is changing in radical ways. On the
one hand, data science and big data have brought an
unprecedented growth and variety in data sizes,
demanding workloads, data types, and applications. On
the other hand, hardware is no longer a source of
performance as it has been in the last
decades. Instead, it has become a complex, fast
evolving, highly specialized, and heterogeneous
platform that requires considerable tuning and effort
to use optimally. In this talk I will discuss the
problem, arguing that there is an opportunity for
specialized designs based on FPGAs and showing the
challenges to data processing resulting from modern
hardware. I will illustrate the points with examples
from research and recent developments from industry to
argue there is a significant opportunity for FPGAs in
data centers if one focuses on the correct problems
and finds the proper architecture for the complete
system.
Gustavo Alonso is a professor at the
Department of Computer Science of ETH Zurich (ETHZ) in
Switzerland, where he is a member of the Systems
Group. Gustavo has a M.S. and a Ph.D. in Computer
Science from UC Santa Barbara. Before joining ETHZ, he
was at the IBM Almaden Research Center. His research
interests encompass almost all aspects of systems,
from design to run time of distributed systems and
databases, with an emphasis on system
architecture. Current research is related to
multi-core architectures, large clusters, FPGAs, and
big data, mainly working on adapting traditional
system software (OS, database, middleware) to modern
hardware platforms. Gustavo is a Fellow of the ACM and
of the IEEE.

Christoph Hagleitner
IBM, CH
Heterogeneous Computing
Systems in Cloud Datacenters
(slides)
Cloud computing is at the core of the ongoing
revolution inside the IT industry and the cloud
platform is a central strategic element in IBMs
current transformation. Heterogeneous computing
systems employing GPUs, FPGAs, and custom ASICs
promise to address the performance and
energy-efficiency bottlenecks of homogeneous,
CPU-based datacenter (DC)
infrastructures. FPGAs offer reconfigurability and
superior energy-efficiency, but have only established
themselves in niche markets like networking and
storage appliances in current DCs. There are two
complementary approaches to establish heterogeneous
computing systems in cloud datacenters: The first is
based on heterogeneous Supernodes that tightly couple
compute resources to multi-core CPUs and their
coherent memory system via high-bandwidth, low latency
interconnects like CAPI or NVlink. The second approach
is based on the disaggregation of DC resources, where
the individual compute, memory, and storage resources
are connected only via the network fabric and can be
individually optimized and scaled in line with the
cloud paradigm. This talk will map the DC workloads in
the areas of cognitive computing, HPC, and IoT to the
proposed system architectures and explore where FPGAs
can provide differentiation.
Christoph Hagleitner leads the
accelerator technologies group at the IBM Research
Zurich Lab (ZRL) in Ruschlikon, Switzerland. The group
focuses on (hardware-accelerated) heterogeneous
computing systems for cloud and HPC. Applications
include big-data analytics and cognitive computing. He
obtained a diploma degree in Electrical Engineering
from ETHZ, Switzerland in 1997 and and a Ph.D. degree
for a thesis on CMOS-integrated Microsensors from
ETHZ, Switzerland in 2002. In 2003 he joined IBM
Research to work on the system architecture of a novel
probe-storage device (millipede-project). In
2008, he started to build up a new research group in
the area of accelerator technologies. The team
initially focused on on-chip accelerator cores and
gradually expanded its research to heterogeneous
systems and their applications.

P. K. Gupta
Intel, US
Accelerating Datacenter Workloads
(slides)
Developers are continually challenged with solving
workloads that are increasing in diversity and
complexity. Modern workloads include use cases for
cloud, networking, HPC and storage which have
different attributes. We will discuss strategies and
tools to accelerate these workloads using FPGAs,
including development environments that make it easier
to deploy and manage FPGAs in the datacenter.
P. K. Gupta (PK) is the General
Manager of the Xeon+FPGA Products in the Data Center
Group at Intel Corporation. He is responsible for
developing the Xeon+FPGA product for accelerating
cloud workloads. PK has been working on accelerator
technologies for servers for 10 years. Prior to that,
he was the CTO of Intel's Modular Communications
Platform Division and the Director of Engineering of
Network Building Block Division in Intel's
Communications Infrastructure Group. PK has been with
Intel since the acquisition of Dialogic in 1999. He
joined Dialogic in 1996 and held various engineering
positions, including the VP of Engineering. Prior to
Dialogic, PK was at Hughes where he led the
development of satellite and cellular communication
products. PK holds 15 patents and is the author of
numerous papers for journals and conference
proceedings. PK holds a PhD in Electrical Engineering
from University of Rhode Island and a MBA from the
Wharton Business School at the University of
Pennsylvania.

Tomas Evensen
Xilinx, US
A Software Developer's
Journey into a Deeply Heterogeneous World
(slides)
Embedded software developers have always had to deal
with more than just the code running on a
processor. To be effective you had to understand the
underlying hardware, including caches and
interrupts. But with today's deeply heterogeneous
architectures, including multiple types of
microprocessors, FPGAs, DSPs, and GPUs, the software
developer is being asked to partition the application
to run efficiently across hardware that sometimes does
not even remotely resemble the CPU you are used
to. Using the Xilinx MPSoC as an example, this talk
will cover what it takes to create an effective
software environment that can handle the heterogeneous
nature of modern embedded SoCs, including using
multiple operating systems and putting some of your C
code in the FPGA.
Tomas Evensen is Chief Technology
Officer, Embedded Software at Xilinx. In this role he
is responsible for the embedded software strategy for
Xilinx All Programmable SoCs. Prior to joining Xilinx,
Evensen was Chief Technology Officer at Wind River for
seven years, as well as GM for the Wind River Tools
Division. Before that he was the creator of the Diab
Data C/C++ compilers. Evensen received his MSEE at the
Royal Institute of Technology in Stockholm, Sweden.
 LT / Régis Colombo")
Tutorials & Workshops
The following tutorials and workshops took place before and after the main conference.
|
Monday 29th Aug |
Friday 2nd Sep |
|||||
|---|---|---|---|---|---|---|
| morning | afternoon | morning | afternoon | |||
|
Tutorial TM1 Embedded Design Using LabVIEW Real-Time and FPGA |
Tutorial TF1 Embedded Systems and OpenCL on the Cyclone V SoC |
|||||
|
Tutorial TM2 Hyperscale FPGA Research on Catapult |
Tutorial TF2 Pynq for Zynq Devices |
|||||
|
Tutorial TM3 Energy-efficient Acceleration for Neuro-inspired Computing On-a-Chip |
Tutorial TM4 Practical on Benchmarking Real-Time and Energy Constrained 3D Robot Vision Applications with SLAMBench |
Tutorial TF3 Accelerating Big Data Processing with Hadoop, Spark, and Memcached on Datacenters on Modern Clusters |
||||
|
Workshop WM1 FPGAs for Software Programmers (FSP 2016) |
Workshop WF1 Soft Errors and Programmable Logic (SEPL 2016) |
|||||
|
Workshop WF2 Security in Reconfigurable Devices: Challenges and Solutions (SecRec 2016) |
Workshop WF3 Reconfigurable Computing — From Embedded Systems to Reconfigurable Hyperscale Servers |
|||||
| morning | afternoon | morning | afternoon | |||
|
Monday 29th Aug |
Friday 2nd Sep |
|||||
⋄
Tutorial TM1
Embedded Design Using
LabVIEW Real-Time and FPGA
Organizers: Jose Albuquerque Silva, Maha Moatemri, and
Joseph Tagg (National Instruments, US)
Monday,
9:00am–5:30pm
Room: 2A
Using high level synthesis (HLS) and an inherently parallel programming language, National Instruments (NI) provides software developers a powerful and efficient way to capture complex designs. This seminar explores the LabVIEW graphical embedded development tools and National Instruments off-the-shelf prototyping and deployment-ready systems. Discover first-hand how to design, prototype, and deploy real-time applications using NI LabVIEW Real-Time and FPGA programming tools and NI RIO hardware. Explore leading-edge control design tools and techniques to improve your design efficiency for custom systems and machines. Learn about closed loop control design, simulation, implementation, and monitoring including PID control and FPGA based machine analysis. During the workshop attendees will have also the opportunity to learn how to design real systems with NI myRIO and thus connecting the acquired knowledge with the teaching experience. NI myRIO is an embedded hardware device developed for teaching applications and designed for developing real, complex engineering systems using a dual-core ARM® CortexTM-A9 real-time processor and customized I/O with a Xilinx FPGA.
For more details, please visit this website.
⋄
Tutorial TM2
Hyperscale FPGA
Research on Catapult
Organizers: Andrew Putnam (Microsoft, US) and Derek Chiou
(Microsoft and University of Texas Austin,
US)
Monday, 9:00am–5:30pm
Room: INF3
(EPFL)
The Microsoft Catapult system is a multi-FPGA reconfigurable fabric designed for integration with modern hyperscale datacenters. Microsoft has donated two large systems for use by both academic and commercial researchers—one at EPFL, and one at TACC at the University of Texas (Austin). Similar hardware is available in very limited supply for individual systems. The goal of this donation is to facilitate large-scale, multi-FPGA research. This tutorial will introduce students to the Catapult hardware, software, and systems. Basic compilation of simple roles will be covered, as well as writing software to interact with those roles. We will also briefly cover the use of the EPFL and TACC systems, as well as any questions about promising research directions using the Catapult hardware.
⋄
Tutorial TM3
Energy-efficient
Acceleration for Neuro-inspired Computing On-a-Chip
Organizers: Yu Cao, Jae-sun Seo, and Yu Wang (Arizona
State University, US)
Monday,
9:00am–12:30pm
Room: 3A
Neuro-inspired computing, has made enormous progress in recent years. Yet their performance on hardware is still limited by the scale of computation and the architecture of existing CPUs/GPUs. While special purpose hardware solutions help bring expensive algorithms to a low-power processor, limitations still exist in homogeneous architecture, memory footprint, communication, and online learning capability, especially for mobile/wearable systems with extreme power constraints. This tutorial will present our latest knowledge of hardware acceleration from multiple aspects. Examples include model/memory compression, data precision, architectural optimization, circuit operation, emerging devices, and neuromorphic motifs. These techniques will effectively reduce the computation complexity and improve the mapping of the algorithms to various hardware platforms.
For more details, please visit this website.
⋄
Tutorial TM4
Practical on
Benchmarking Real-Time and Energy Constrained 3D Robot
Vision Applications with SLAMBench
Organizers: Bruno Bodin, Luigi Nardi, and Harry Wagstaff
(University of Edinburgh, UK)
Monday,
2:15pm–5:30pm
Room: 3A
During this tutorial we propose a practical on the robotics vision SLAMBench benchmarking framework. Simultaneous Localisation And Mapping (SLAM) systems aim to perform real-time localisation of the camera and 3D mapping “simultaneously” for a camera moving through an unknown environment. The SLAMBench benchmarking framework is a publicly-available software framework which represents a starting point for quantitative, comparable and validatable experimental research to investigate trade-offs in performance, accuracy and energy consumption of SLAM algorithms. Our goal is to ensure that attendees can install andrun the framework on their machine during the tutorial. No previous knowledge of computer vision is required. Invited speakers will talk about their experience with SLAMBench.
For more details, please visit this website.
⋄
Tutorial TF1
Embedded Systems and
OpenCL on the Cyclone V SoC
Organizer: Kevin Nam (Altera, US)
Friday,
9:00am–5:30pm
Room: 2BC
The integration of a CPU and FPGA into an SoC allows the development of exciting applications that benefit from the strengths of each half. In this tutorial we will look at designing such applications using the Cyclone V SoC device. We will begin by examining the Cyclone V SoC device architecture, and writing baremetal code. We will then learn how to use a Linux environment to develop and run software programs that communicate with circuits placed inside the FPGA. Starting from the basics of running Linux on the Cyclone V SoC board, we will work our way up to designing a hardware-accelerated Linux application that offloads computation to a custom circuit placed in the FPGA. The tutorial will conclude with an introduction to the Altera OpenCL SDK, which provides a high-level design methodology for creating hardware-accelerated applications that use Altera FPGAs.
For more details, please visit this website.
⋄
Tutorial TF2
Pynq for Zynq Devices
Organizers: Patrick Lysaght and Cathal McCabe (Xilinx,
US)
Friday, 9:00am–5:30pm
Room:
3A
Pynq is a new open-source framework for designing with Xilinx Zynq devices. Pynq enables programmers who design embedded systems to exploit the capabilities of Zynq APSoCs without having to use ASIC-style, CAD tools to design programmable logic circuits. Instead the APSoC is programmed in Python and the code is developed and tested directly on the embedded system. The programmable logic circuits are imported as hardware libraries and programmed through their APIs, in essentially the same way that software libraries are imported and programmed. The framework combines four main elements: (1) the use of a high-level productivity language, Python in this case; (2) Python-callable hardware libraries based on FPGA overlays; (3) a web-based architecture incorporating the open-source Jupyter Notebook infrastructure served from Zynq's embedded processors; and (4) Jupyter Notebook's client-side, web apps. The result is a web-centric programming environment that enables software programmers to work at higher levels of design abstraction and to re-use both software and hardware libraries. This tutorial will give a hands-on introduction to Pynq.
⋄
Tutorial TF3
Accelerating Big Data
Processing with Hadoop, Spark, and Memcached on Datacenters
on Modern Clusters
Organizers: DK Panda and Xioyi Lu (The Ohio State
University, US)
Friday,
9:00am–12:30pm
Room: 2A
Apache Hadoop and Spark are gaining prominence in handling Big Data and analytics. Similarly, Memcached in Web 2.0 environment is becoming important for large-scale query processing. These middleware are traditionally written with sockets and do not deliver best performance on datacenters with modern high performance networks. In this tutorial, we will provide an in-depth overview of the architecture of Hadoop components (HDFS, MapReduce, RPC, HBase, etc.), Spark and Memcached. We will examine the challenges in re-designing the networking and I/O components of these middleware with modern interconnects, protocols (such as InfiniBand, iWARP, RoCE, and RSocket) with RDMA and storage architecture. Using the publicly available software packages in the High-Performance Big Data (HiBD, http://hibd.cse.ohio-state.edu) project, we will provide case studies of the new designs for several Hadoop/Spark/Memcached components and their associated benefits. Through these case studies, we will also examine the interplay between high performance interconnects, storage systems (HDD and SSD), and multi-core platforms to achieve the best solutions for these components.
For more details, please visit this website.
⋄
Workshop WM1
FPGAs for Software
Programmers (FSP 2016)
Organizers: Andreas Koch (Technische Universität
Darmstadt, DE) and Markus Weinhardt (Hochschule Osnabrück,
DE)
Proceedings Chair: Christian Hochberger (Technische
Universität Darmstadt, DE)
Monday,
9:00am–5:30pm
Room: 2BC
The aim of this workshop is to make FPGA and reconfigurable technology accessible to software programmers. Despite their frequently proven power and performance benefits, designing for FPGAs is mostly an engineering discipline carried out by highly trained specialists. With recent progress in high-level synthesis, a first important step towards bringing FPGA technology to potentially millions of software developers was taken.
For more details, please visit this website.
⋄
Workshop WF1
Soft Errors and
Programmable Logic (SEPL 2016)
Organizers: Mike Wirthlin (Brigham Young University, US)
and Mike Hutton (Altera, US)
Friday,
9:00am–5:30pm
Room: 3B
Programmable devices are very attractive for a variety of applications due to their high levels of logic integration, their flexibility during the project lifetime, and their reconfigurability. However, SRAM-based FPGAs are particularly susceptible to single-event upsets due to ionizing radiation found in the terrestrial environment, high-altitude applications, space, and unique radiation environments such as high-energy physics. The objective of this workshop is to share information and results related to the reliable use of SRAM-based FPGAs in the presence of single-event effects. This topic is of interest to users of FPGAs in a variety of unique environments such as space, avionics, high-reliability, FPGA-based data centers, and high-energy physics. This topic will be of increasing interest to a variety of users as the densities of FPGAs continue to increase and the effects of ionizing radiation play a more important part of large FPGA-based systems.
For more details, please visit this website.
⋄
Workshop WF2
Security in
Reconfigurable Devices: Challenges and Solutions (SecRec
2016)
Organizers: Lejla Batina (Radboud University, NL),
Francesco Regazzoni (USI, CH), Ricardo Chaves (INESC-ID,
PT), Nele Mentens (KU Leuven, BE), and Tim Güneysu
(University of Bremen, DE)
Friday,
9:00am–12:30pm
Room: 3C
Reconfigurable systems are used to control critical application or to handle sensitive information. To safely and reliably implement such systems, it is of paramount importance that designers have a complete awareness of the risks to be avoided, the main security threats, and the most advanced protection available. Similar to other digital circuits, designs implemented using FPGAs are susceptible to physical attacks and to hardware Trojans. Nevertheless, FPGAs offer new and unique possibilities for implementing secure features, including quantum resistant algorithms, and for guaranteeing robustness against reverse engineering. The SecRec Workshop aims to bring researchers and experts together to discuss current and future research directions regarding threats, attacks, design methodologies, and basic blocks currently used to address security problems using reconfigurable hardware.
For more details, please visit this website.
⋄
Workshop WF3
Reconfigurable
Computing — From Embedded Systems to Reconfigurable
Hyperscale Servers
Organizers: Mario Porrmann (Bielefeld University, DE),
Zain Ul‐Abdin (Halmstad University, SE), and Madhura
Purnaprajna (Amrita University, IN)
Friday,
2:15pm–5:30pm
Room: 3C
Reconfigurable computing platforms, which offer massive parallelism coupled with the capability of run‐time adaptation to changing application requirements are becoming core components of the information processing in embedded systems with high computational demand but limited energy budget. In parallel to their utilization for IoT devices and in cyber physical systems, reconfigurable systems are used together with GPGPUs in data centres for high performance and cloud computing. The synergistic use of multiprocessing techniques and reconfigurable parallelism has shown orders of magnitude improvements in performance, power efficiency, and cost for a wide range of applications. Partial reconfiguration—a research topic for two decades—is becoming mainstream for embedded systems and is seen as an important requirement for efficient utilization in HPC and cloud computing. However, developing systems and applications that employ such architectures still poses many challenges, which are currently tackled in several research projects. In this workshop, we want to bring together researchers from a wide variety of international projects to share their achievements and innovations in the area of reconfigurable computing, ranging from embedded systems to reconfigurable hyperscale servers. The workshop will provide a platform for open discussion of ongoing research with interested attendees from industry and academia.
For more details, please visit this website.
 LT / Bernard Bissat")
Awards

The Michal Servit Award, to the most outstanding paper in the area of design algorithms, methods, and CAD tools for FPGAs and self-aware systems, was awarded to An Evaluation on the Accuracy of the Minimum Width Transistor Area Models in Ranking the Actual Layout Area of FPGA Architectures by Farheen Khan and Andy Ye (Ryerson University, CA).

The Stamatis Vassiliadis Award, to the most outstanding paper in the area of architecture and applications, was awarded to An Investigation into a Circuit Based Supply Chain Analyzer for FPGAs by Jacob Couch and John Arkoian (Johns Hopkins University, US).

The FPL'16 Community Award, in appreciation of an outstanding research contribution to the FPL community through publicly accessible IP that can be used and extended by others in future research, was awarded to JetStream: An Open-Source High-performance PCI Express 3 Streaming Library for FPGA-to-Host and FPGA-to-FPGA Communication by Malte Vesper and Dirk Koch (University of Manchester, UK), Kizheppatt Vipin (Mahindra École Centrale, IN), and Suhaib A. Fahmy (University of Warwick, UK).
 LT / Hugues Siegenthaler")
Registration
To register for the conference and for all tutorials workshops, please visit the registration site. After registration, you will receive by e-mail a personal link that can be used to update your registration at any time (e.g., to participate in tutorials or to add tickets for the social event). If you are unable to pay by credit card because of exceptional circumstances, please register as usual (but leaving the billing info blank) and contact the Registration Chairs. Please note that registrations are not refundable.
Early registration ends at midnight AoE on 15th July 2016. Online registration will remain open until the conference begins. On-site registration will be available at the Late Registration rates and only by credit card or PayPal.
|
Early (before 15th July) |
Late (from 16th July) |
|
|---|---|---|
|
Main conference (full registration) |
625 CHF | 825 CHF |
|
Main conference (students) |
335 CHF | 425 CHF |
|
Any tutorials or workshops on Monday |
60 CHF/day (if registered for the main conference) 125 CHF/day (otherwise) |
|
|
Any tutorials or workshops on Friday |
60 CHF/day (if registered for the main conference) 125 CHF/day (otherwise) |
|
|
Additional tickets for the social event |
120 CHF | |
|
Additional pages (max 2, full papers only) |
150 CHF | |
 LT / Régis Colombo")
Accommodation
A number of rooms have been reserved for the conference in various hotels. They will be kept available for the FPL'16 participants on a first-come first-served basis until a date specified by the hotel (usually between end of June and early August). Below is the offering by these hotels; to book a reserved room in any of these hotels, you should e-mail directly the hotel (envelope link in the table) and mention "FPL16" as a reference to the reservation. Note that at the time of this writing some of these hotels already look fully booked on common travel websites. Please also note that the reservation is only a courtesy by the hotels to our participants.
| Hotel | Book by | Offer | Breakfast | |
|---|---|---|---|---|
|
Alpha-Palmiers ★★★★ |
5% discount if booked directly | |||
|
Continental ★★★★ |
27th July |
Single: 175 CHF Double (1 p.): 220 CHF Double (2 pp.): 280 CHF |
incl. | |
|
Starling ★★★★ |
26th July |
Double (1 p.): 160 CHF Double (2 pp.): 195 CHF |
incl. | |
|
Victoria ★★★★ |
27th July |
Single: 192 CHF Double (1 p.): 222 CHF |
incl. | |
|
46a ★★★ |
28th June |
Studio (1 p.): 145 CHF Studio (2 pp.): 160 CHF |
incl. | |
|
Aulac ★★★ |
10th August |
Single: 145 CHF Large single: 160 CHF Double: 190 CHF |
incl. | |
|
Crystal ★★★ |
29th July |
Single: 131 CHF Double (1 p.): 161 CHF Double (2 pp.): 181 CHF |
incl. | |
|
Du Port ★★★ |
8th August |
Single (town side): 145 CHF Double (2 pp., lake side): 195 CHF Double (2 pp., town side): 175 CHF |
incl. | |
|
LHOTEL ★★★ |
25th July |
Single: 102.50 CHF Double (2 pp.): 142.50 CHF |
14 CHF | |
|
SwissTech ★★★ |
15th July | Single: 120 CHF | 11 CHF | |
|
Ibis ★★ |
13th August |
Double (1 p., 28/08): 126 CHF Double (1 p., 29/08 and 01/09): 155 CHF Double (1 p., 30/08 and 31/08): 161 CHF |
no | |
|
Jeunotel (Youth Hostel) |
30th June |
Single: 87 CHF Double: 59 CHF/person Quadruple: 40 CHF/person |
no |
For your convenience, the map below indicates the location of all of the above hotels together with the main sites of the conference and some touristic landmarks. Note that the SwissTech Hotel is right on the side of the SwissTech Convention Centre and literally on the platform of the metro connecting EPFL with the city centre. Most of the rooms have been reserved there.
 LT / Régis Colombo")
Local Transportation
The best means to reach Lausanne from all Swiss airports is train. You can find the most convenient connections from the CFF website or using Google Maps. Both Geneva and Zurich airports have a train station inside the building and direct trains to Lausanne. You should typically take one-way tickets (return tickets are valid only for the same day) and get regular tickets (most Swiss residents have a 1/2-price card). A second class regular ticket to/from Geneva Airport costs 27 CHF and one to/from Zurich Airport costs 77 CHF. Second class is quite comfortable; first class, depending on the route and times, may have the advantage of more free seats available (but not always!).
Public transportation in Lausanne is fairly well developed and efficient. You can find the most convenient connections and all timetables from the TL website or, again, using Google Maps. In particular, you can find on the TL website the network map in PDF. To reach EPFL and STCC, the most convenient line is m1, a metro line, and the stop you want is named, unimaginatively, EPFL. STCC is immediately recognizable from the m1 stop. Note that you could take m1 to EPFL both from the city centre (stop Lausanne-Flon) as well as from the Renens train station (on the Geneva – Lausanne line, but few trains from the airport stop there). Finally, everyone staying in a hotel in Lausanne will receive a free daily ticket, so you should not be concerned by how to obtain tickets.
The use of private cars to come to Lausanne is usually not a recommended option, unless the hotel offers parking spaces (free and unlimited street parking is almost inexistent in the city centre). Coming to EPFL by private car is also not very convenient: there is no public parking at STCC and parking at EPFL requires you to purchase daily parking passes at the central information desk. Please consider that public transportation is much more convenient.
Finally, if you need to find a place at EPFL, you may find useful the interactive map of EPFL
 LT / Régis Colombo")
Tourism
Late summer is a great time to visit the region of Lake Geneva and Switzerland. There are many websites with abundant information on Lausanne and Switzerland.
![]()
The
official Lausanne tourism website.
![]()
The
official Lake Geneva Region tourism
website.
![]()
The
official Switzerland tourism website.
![]()
The
official Gran Tour of Switzerland website.
![]()
![]()
And there is a
City Guide Lausanne app available for
both Android and iOS.
 LT / Régis Colombo")
Important Dates
Abstract submission deadline: 20th March 2016
Paper submission deadline: 27th March 2016 AoE (please note: no extensions!)
Demo night, PhD forum, tutorials, and workshops submission deadline: 8th May 2016
Notifications: around 15th June 2016
Final manuscripts deadline: 3rd July 2016
Early registration deadline: 15th July 2016
Online registration deadline: 22nd August 2016
.jpg "(C) Alain Herzog")
Calls for Contributions
Here is the final Call for Contributions in PDF.
Here is the final Call for PhD Forum and Demo Night Contributions in PDF.
The conference proceedings will me made available online at the FPL 2016 venue and will be published through IEEE Xplore after the conference.
.jpg "(C) Alain Herzog")
Submissions
Authors are required to use the standard IEEE templates in format A4 and not to include page numbers, to ensure compatibility with IEEE Xplore. Templates for LaTeX and Microsoft Word 2003 are available directly from IEEE.
FPL 2016 uses a double-blind reviewing system. Manuscripts must not identify authors or their affiliations; those that do will not be considered. Exceptions may be allowed with prior approval of the Programme Chairs, in cases where the authors’ identity is vital to evaluating the paper (e.g., papers presenting updates of infrastructure used by the FPGA community). References to the authors’ prior work should be made in the 3rd person, in the same way one would reference work by others. If necessary to maintain anonymity, citations may be shown as "Removed for blind review", but consider that this may impede a thorough review if the removed citation is crucial to understanding the submission.
Papers can be submitted for one of the following categories (please note the later deadline for the last two types of papers). All papers will be published in the proceedings and will appear in IEEE Xplore. Strict paper length limitations are as follows:
| Full papers | 8 pages + up to 2 additional pages which can be purchased at the time of registration for 150 CHF/page + references (i.e., references are not counted in the page budget) |
| Short papers | 4 pages, including references |
| PhD Forum papers | 2 pages, including references |
| Demo Night papers | 1-page abstract, including references |
Use this submission site to submit your paper. Please note that the submission of the full- and short-paper abstracts by the relevant deadline is mandatory and that deadlines are not going to be extended.
 LT / Régis Colombo")
Organizing Committee
General Chairs
- Paolo Ienne, EPFL, CH
- Walid Najjar, University of California Riverside, US
Programme Chairs
- Jason Anderson, University of Toronto, CA
- Philip Brisk, University of California Riverside, US
Tutorial and Workshop Chairs
- Pierre‐Emmanuel Gaillardon, University of Utah, US
- Michael Hübner, Ruhr-Universität Bochum, DE
PhD Forum, Demo Night, and Industrial Events Chairs
- Mirjana Stojilović, HEIG‐VD, CH
- Yann Thoma, HEIG‐VD, CH
Proceedings Chair
- Walter Stechele, TU München, DE
Publicity Chair
- Kubilay Atasu, IBM Research – Zurich, CH
Local Arrangements Chair
- Chantal Schneeberger, EPFL, CH
Local Arrangements Team
- Mikhail Asiatici, EPFL, CH
- Andrew Becker, EPFL, CH
- Lana Josipović, EPFL, CH
- Ana Petkovska, EPFL, CH
- Grace Zgheib, EPFL, CH
Registration Chairs
- Andrew Becker, EPFL, CH
- Grace Zgheib, EPFL, CH
.jpg "(C) Paolo Ienne")
Programme Committee
- Michael Adler, Intel, US
- Hideharu Amano, Keio University, JP
- David Andrews, University of Arkansas, US
- Sameh Asaad, IBM, US
- Kubilay Atasu, IBM, CH
- Peter Athanas, Virginia Tech, US
- Trevor Bauer, Xilinx, US
- Samuel Bayliss, Xilinx, US
- Kia Bazargan, University of Minnesota, US
- Jürgen Becker, Karlsruher Institut für Technologie, DE
- Tobias Becker, Maxeler Technologies, UK
- Pascal Benoit, Université Montpellier 2, FR
- Neil Bergmann, University of Queensland, AU
- Koen Bertels, Technische Universiteit Delft, NL
- Vaughn Betz, University of Toronto, CA
- Dustyn Blasig, National Instruments, US
- Michaela Blott, Xilinx, IE
- Christophe Bobda, University of Arkansas, US
- Cristiana Bolchini, Politecnico di Milano, IT
- Christos Bouganis, Imperial College London, UK
- Eli Bozorgzadeh, University of California Irvine, US
- Gordon Brebner, Xilinx, US
- Stephen Brown, Altera, CA
- João M. P. Cardoso, Universidade do Porto, PT
- Benjamin Carrion Schafer, Hong Kong Polytechnic University, HK
- Luigi Carro, Universidade Federal do Rio Grande do Sul, BR
- Deming Chen, University of Illinois at Urbana-Champaign, US
- Peter Cheung, Imperial College London, UK
- Kiyoung Choi, Seoul National University, KR
- Paul Chow, University of Toronto, CA
- Jason Cong, University of California Los Angeles, US
- Philippe Coussy, Université de Bretagne Sud, FR
- Jose Gabriel Coutinho, Imperial College London, UK
- Rene Cumplido, Instituto Nacional de Astrofisica, MX
- Martin Danek, Daiteq, CZ
- Anup Das, University of Southampton, UK
- Sabya Das, Xilinx, US
- Eduardo de la Torre, Universidad Politécnica de Madrid, ES
- André DeHon, University of Pennsylvania, US
- Steven Derrien, Université de Rennes 1, FR
- Oliver Diessel, University of New South Wales, AU
- Pedro Diniz, University of Southern California, US
- Apostolos Dollas, Technical University of Crete, GR
- Carl Ebeling, Altera, US
- Suhaib A. Fahmy, University of Warwick, UK
- Fabrizio Ferrandi, Politecnico di Milano, IT
- Elliott Fleming, Intel, US
- Blair Fort, University of Toronto, CA
- Roberto Giorgi, Università di Siena, IT
- Diana Goehringer, Ruhr-Universität Bochum, DE
- Guy Gogniat, Université de Bretagne Sud, FR
- Maya Gokhale, Lawrence Livermore National Laboratory, US
- Kees Goossens, Technische Universiteit Eindhoven, NL
- Ann Gordon-Ross, University of Florida, US
- David Greaves, University of Cambridge, UK
- Jonathan Greene, Microsemi, US
- Yajun Ha, National University of Singapore, SG
- Yuko Hara-Azumi, Tokyo Institute of Technology, JP
- Reiner Hartenstein, Technische Universität Kaiserslautern, DE
- Martin Herbordt, Boston University, US
- James C. Hoe, Carnegie Mellon University, US
- Michael Hübner, Ruhr-Universität Bochum, DE
- Miaoqing Huang, University of Arkansas, US
- Eddie Hung, Imperial College London, UK
- Paolo Ienne, EPFL, CH
- Arpith Jacob, IBM, US
- Nachiket Kapre, Nanyang Technological University, SG
- Sinan Kaptanoglu, Microsemi, US
- Wolfgang Karl, Karlsruher Institut für Technologie, DE
- Ryan Kastner, University of California San Diego, US
- Alireza Kaviani, Xilinx, US
- Tom Kean, Algotronix, UK
- Udo Kebschull, Goethe Universität Frankfurt, DE
- Andrew Kennings, University of Waterloo, CA
- Kenneth Kent, University of New Brunswick, CA
- Taemin Kim, Intel, US
- Kenji Kise, Tokyo Institute of Technology, JP
- Vipin Kizheppatt, Mahindra École Centrale, IN
- Andreas Koch, Technische Universität Darmstadt, DE
- Dirk Koch, University of Manchester, UK
- Jan Korenek, Brno University of Technology, CZ
- Akash Kumar, Technische Universität Dresden, DE
- Martin Langhammer, Altera, UK
- Luciano Lavagno, Politecnico di Torino, IT
- Miriam Leeser, Northeastern University, US
- Guy Lemieux, University of British Columbia, CA
- Philip Leong, University of Sydney, AU
- Wayne Luk, Imperial College London, UK
- Patrick Lysaght, Xilinx, US
- Wai-Kei Mak, National Tsing Hua University, TW
- Tsutomu Maruyama, University of Tsukuba, JP
- Cathal McCabe, Xilinx, IE
- Nele Mentens, Katholieke Universiteit Leuven, BE
- Antonio Miele, Politecnico di Milano, IT
- Roger Moussalli, IBM, US
- Walid Najjar, University of California Riverside, US
- Brent Nelson, Brigham Young University, US
- Smail Niar, Université de Valenciennes, FR
- David Novo, Université Montpellier 2, FR
- Jose Nunez-Yanez, University of Bristol, UK
- Gianluca Palermo, Politecnico di Milano, IT
- Ioannis Papaefstathiou, Technical University of Crete, GR
- Cameron Patterson, Virginia Tech, US
- Christian Pilato, Columbia University, US
- Thilo Pionteck, Universität zu Lübeck, DE
- Marco Platzner, Universität Paderborn, DE
- Christian Plessl, Universität Paderborn, DE
- Dionisios Pnevmatikatos, Technical University of Crete, GR
- Daniel Poznanovic, Cray, US
- Madhura Purnaprajna, Amrita University, IN
- Rodric Rabbah, IBM, US
- Kyle Rupnow, Advanced Digital Sciences Center, SG
- Mazen Saghir, American University of Beirut, LB
- Kentaro Sano, Tohoku University, JP
- Marco D. Santambrogio, Politecnico di Milano, IT
- Paul Schumacher, Xilinx, US
- Olivier Sentieys, Université de Rennes 1, FR
- Muhammad Shafique, Karlsruher Institut für Technologie, DE
- Lesley Shannon, Simon Fraser University, CA
- Cristina Silvano, Politecnico di Milano, IT
- Nicolas Sklavos, University of Patras, GR
- Ioannis Sourdis, Chalmers Tekniska Högskola, SE
- Dirk Stroobandt, Universiteit Gent, BE
- Henry Styles, Xilinx, US
- Jürgen Teich, Friedrich-Alexander-Universität Erlangen-Nürnberg, DE
- Russ Tessier, University of Massachusetts Amherst, US
- David Thomas, Imperial College London, UK
- Tim Todman, Imperial College London, UK
- Hiroyuki Tomiyama, Ritsumeikan University, JP
- Lionel Torres, Université Montpellier 2, FR
- Jim Tørresen, Universitetet i Oslo, NO
- Steve Trimberger, Xilinx, US
- Wim Vanderbauwhede, University of Glasgow, UK
- Tanya Vladimirova, University of Leicester, UK
- Qiang Wang, Huawei, US
- John Wawrzynek, University of California Berkeley, US
- Norbert Wehn, Universität Kaiserslautern, DE
- Markus Weinhardt, Hochschule Osnabrück, DE
- Gabriel Weisz, Information Sciences Institute, US
- Steve Wilton, University of British Columbia, CA
- Michael Wirthlin, Brigham Young University, US
- Stephan Wong, Technische Universiteit Delft, NL
- Roger Woods, Queen's University Belfast, UK
- Sotirios Xydis, National Technical University of Athens, GR
- Yoshiki Yamaguchi, University of Tsukuba, JP
- Wei Zhang, Hong Kong University of Science and Technology, HK
- Zhiru Zhang, Cornell University, US
- Daniel Ziener, Friedrich-Alexander-Universität Erlangen-Nürnberg, DE
- Peter Zipf, Universität Kassel, DE
 LT / Régis Colombo")
Steering Committee
Chairman
- Patrick Lysaght, Xilinx, US
- Jürgen Becker, Karlsruher Institut für Technologie, DE
- Koen Bertels, Technische Universiteit Delft, NL
- Eduardo Boemo, Universidad Autónoma de Madrid, ES
- João M. P. Cardoso, Universidade do Porto, PT
- Peter Y. K. Cheung, Imperial College London, UK
- Martin Danek, Daiteq, CZ
- Apostolos Dollas, Technical University of Crete, GR
- Fabrizio Ferrandi, Politecnico di Milano, IT
- Manfred Glesner, Technische Universität Darmstadt, DE
- John Gray, consultant, UK
- Reiner Hartenstein, Technische Universität Kaiserslautern, DE
- Andreas Herkersdorf, Technische Universität München, DE
- Udo Kebschull, Goethe Universität Frankfurt, DE
- Wayne Luk, Imperial College London, UK
- Jari Nurmi, Tampere University of Technology, FI
- Lionel Torres, Université Montpellier 2, FR
- Jim Tørresen, Universitetet i Oslo, NO
- Roger Woods, Queen's University Belfast, UK
 Christof Schuerpf")
Sponsors
Technical Sponsor
Platinum Level
Golden Level


Silver Level



.jpg "(C) Alain Herzog")
Previous Editions
- FPL 2015: London, UK
- FPL 2014: Munich, DE
- FPL 2013: Porto, PT
- FPL 2012: Oslo, NO
- FPL 2011: Chania, GR
- FPL 2010: Milano, IT
- FPL 2009: Prague, CZ
- FPL 2008: Heidelberg, DE
- FPL 2007: Amsterdam, NL
- FPL 2006: Madrid, ES
- FPL 2005: Tampere, FI
- FPL 2004: Leuven, BE
- FPL 2003: Lisbon, PT
- FPL 2002: La Grande-Motte, FR
- FPL 2001: Belfast, UK
- FPL 2000: Villach, AT
- FPL 1999: Glasgow, UK
- FPL 1998: Tallinn, EE
- FPL 1997: London, UK
- FPL 1996: Darmstadt, DE
- FPL 1995: Oxford, UK
- FPL 1994: Prague, CZ
- FPL 1993: Oxford, UK
- FPL 1992: Vienna, AT
- FPL 1991: Oxford, UK
.jpg "(C) LT / Urs Achermann")